Cliente Paho MQTT (Javascript), Envoy, VerneMQ: depuración de desconexiones
Después de desplegar picockpit en mi servidor, se observó un error: el frontend web se desconectaba en intervalos muy regulares.
Esto no estaba presente en el entorno de desarrollo local. Los usuarios de picockpit informaron del mismo error.
Lo he depurado hoy y he aplicado una corrección. Resulta que era un problema de sincronización.
TL;DR cómo arreglar esto
establezca un keepAliveInterval más corto para Paho. 60 segundos es el valor por defecto, pero con las latencias de la red esto conducirá a estos tiempos de espera.
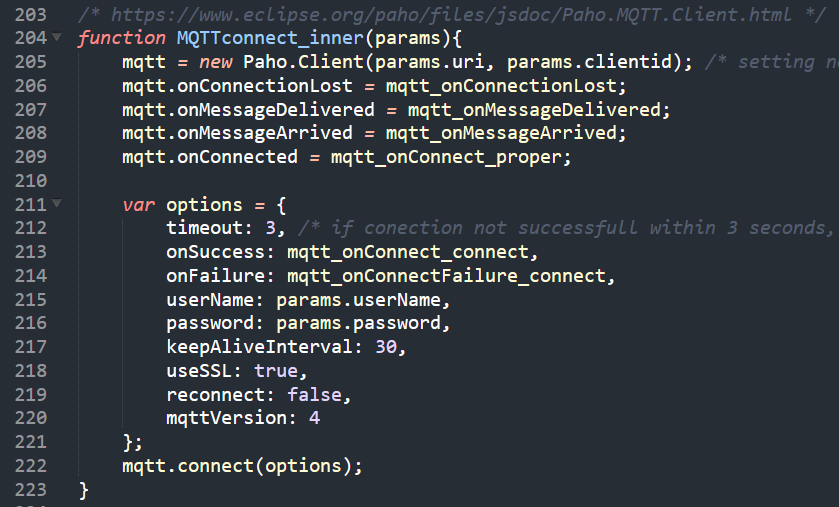
Aquí está mi código para la conexión (dentro de pcp-code.js que es cargado por la página web):
/* https://www.eclipse.org/paho/files/jsdoc/Paho.MQTT.Client.html */
function MQTTconnect_inner(params){
mqtt = new Paho.Client(params.uri, params.clientid); /* configuración de parámetros no necesarios ya que JS no permite pasar parámetros posicionales con nombre */
mqtt.onConnectionLost = mqtt_onConnectionLost;
mqtt.onMessageDelivered = mqtt_onMessageDelivered;
mqtt.onMessageArrived = mqtt_onMessageArrived;
mqtt.onConnected = mqtt_onConnect_proper;var options = {
tiempo de espera: 3, /* si la conexión no tiene éxito en 3 segundos, se considera que ha fallado */
onSuccess: mqtt_onConnect_connect,
onFailure: mqtt_onConnectFailure_connect,
userName: params.userName,
contraseña: params.password,
keepAliveInterval: 30,
useSSL: true,
reconectar: falso,
mqttVersion: 4
};
mqtt.connect(opciones);
}
(reproducido también como imagen)
Pasos de depuración
Cronometraje
Me senté con mi teléfono móvil para cronometrar los tiempos de espera y ver si había un patrón.
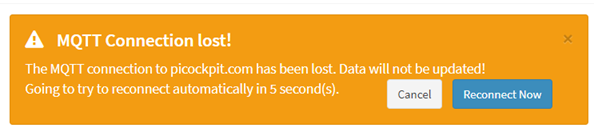
En mi implementación, Paho es reconectado por el código JavaScript circundante cada 10 segundos en el tiempo de espera.
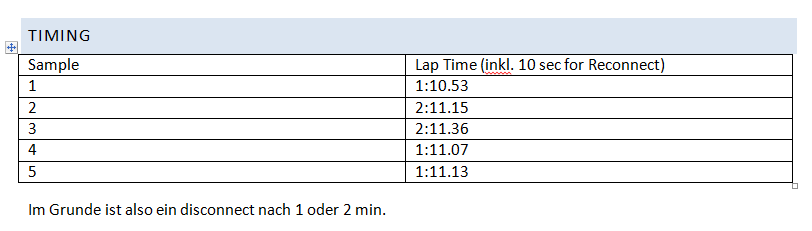
Vemos que el cliente MQTT de Paho javascript pierde la conexión cada minuto o cada dos minutos. Esto ya es un fuerte indicio de que esto es sistemático, posiblemente una desconexión forzada por el servidor.
Consola de JavaScript

El mensaje de error que veo en la consola es:
El WebSocket ya está en estado CLOSING o CLOSED.
En retrospectiva, esto es posiblemente Paho tratando de enviar el PINGREQ pero fallando sólo por un par de segundos o posiblemente microsegundos, ya que el servidor ha desconectado el socket.
NB: Para una mayor compatibilidad con los cortafuegos de la empresa, etc. Ejecuto Paho a través de websockets.
Verificación con otro navegador
He visto este problema con Chrome (mi navegador principal) y con Firefox. Por lo tanto, no se debe a un problema del navegador.
(Este sitio web me ha hecho creer que podría tratarse de algún problema con el navegador: https://github.com/socketio/socket.io/issues/3259)
Depuración de VerneMQ
ver también:
- https://pi3g.com/2019/08/08/vernemq-how-to-disconnect-clients-forceably-per-command-line/
- https://docs.vernemq.com/administration/managing-sessions
Mostrar el client_id completo y el punto de montaje para evitar el truncamiento:
vmq-admin session show -mountpoint -client_id
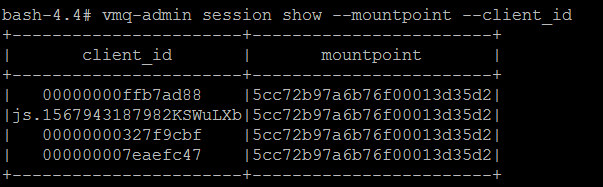
Haz un rastreo:
vmq-admin trace client client-id=js.1567943187982KSWuLXb -mountpoint=5cc72b97a6b76f00013d35d2

Como ves, obtendrás una traza de lo que se envía al cliente y se recibe del mismo.
Iniciando el rastreo de 1 sesión existente para el cliente "js.1567943187982KSWuLXb" con PIDs
[]
MQTT SEND: MP: "5cc72b97a6b76f00013d35d2" CID: "js.1567943187982KSWuLXb" PUBLISH(d0, q0, r0, m0, "pi/000000007eaefc47/com.picockpit/sensors/$state/pi") con payload:
{"wlan_signal_info": "Link Quality=61/70 Signal level=-49 dBm", "cpu_load": 1,4, "net_io_bytes_received": 798582943, "root_partition_used": 2028572672, "net_io_bytes_sent": 1482989984, "soc_temperatu (truncado)
También he visto un PINGREQ() y un PINGRESP(), manteniendo la sesión viva en esta traza:
MQTT RECV: MP: "5cc72b97a6b76f00013d35d2" CID: "js.1567943187982KSWuLXb" PINGREQ()
MQTT SEND: MP: "5cc72b97a6b76f00013d35d2" CID: "js.1567943187982KSWuLXb" PINGRESP()
Así es como se ve la desconexión:
MQTT SEND: MP: "5cc72b97a6b76f00013d35d2" CID: "js.1567943187982KSWuLXb" PUBLISH(d0, q0, r0, m0, "pi/00000000327f9cbf/com.picockpit/sensors/$state/pi") con payload:
{"wlan_signal_info": "Link Quality=68/70 Signal level=-42 dBm", "ram_total_bytes": 969392128, "$uuid": “928ca964-d22e-11e9-9e22-dca632007438”, “disk_io_bytes_written”: 619947008, "root_partition_tota (truncado)
Se ha detenido la sesión de rastreo para js.1567943187982KSWuLXb
Desgraciadamente hay no hay información que esto se debe a un tiempo de espera de un pingreq() del cliente.
Depuración de Envoy
Véase también:
Como no había información de que esto se debiera a un tiempo de espera de pingreq, la sospecha recayó en que envoy se desconectara debido a los tiempos de espera (posiblemente manejando los websockets de forma incorrecta debido a que no establecí alguna configuración correctamente).
Sin embargo, la configuración se aplicó correctamente:
upgrade_configs:
- tipo_de_actualización: "websocket"
habilitado: true
para la ruta correcta (/mqtt)
No hay tiempos de espera, aparte de connect_timeout para los backends (que se establecieron en valores diferentes, seguramente no un minuto).
Para habilitar la salida de depuración desde envoy, tienes que añadir una variable de entorno al docker-compose.yaml:
ambiente:
nivel de registro: depuración
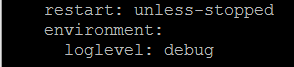
como las últimas líneas de la estrofa para el enviado de servicio
Esto es lo que veo como rastro:
':estado', '101'
"conexión", "actualización
'date', 'Sun, 08 Sep 2019 12:08:36 GMT'
'sec-websocket-accept', 'mWAEi6p3RBFflHkNbxTMbnhaG4I='
'sec-websocket-extensions', 'permessage-deflate; client_max_window_bits=15'
'sec-websocket-protocolo', 'mqtt'
'servidor', 'enviado'
"actualización", "websocket
contenido-longitud", "0
[2019-09-08 12:08:38.757][1][debug][main] [source/server/server.cc:170] flushing stats
[2019-09-08 12:08:43.760][1][debug][main] [source/server/server.cc:170] flushing stats
[2019-09-08 12:08:48.755][1][debug][main] [source/server/server.cc:170] flushing stats
[2019-09-08 12:08:53.759][1][debug][main] [source/server/server.cc:170] flushing stats
[2019-09-08 12:08:58.762][1][debug][main] [source/server/server.cc:170] flushing stats
[2019-09-08 12:09:03.762][1][debug][main] [source/server/server.cc:170] flushing stats
[2019-09-08 12:09:08.762][1][debug][main] [source/server/server.cc:170] flushing stats
[2019-09-08 12:09:13.765][1][debug][main] [source/server/server.cc:170] flushing stats
[2019-09-08 12:09:18.766][1][debug][main] [source/server/server.cc:170] flushing stats
[2019-09-08 12:09:23.766][1][debug][main] [source/server/server.cc:170] flushing stats
[2019-09-08 12:09:28.765][1][debug][main] [source/server/server.cc:170] flushing stats
[2019-09-08 12:09:33.766][1][debug][main] [source/server/server.cc:170] flushing stats
[2019-09-08 12:09:37.190][26][debug][connection] [source/common/network/connection_impl.cc:520] [C9] remote Close
[2019-09-08 12:09:37.190][26][debug][connection] [source/common/network/connection_impl.cc:190] [C9] cerrando socket: 0
[2019-09-08 12:09:37.190][26][debug][client] [source/common/http/codec_client.cc:82] [C9] disconnect. resetting 1 pending requests
[2019-09-08 12:09:37.190][26][debug][client] [source/common/http/codec_client.cc:105] [C9] solicitud restablecida.
[2019-09-08 12:09:37.190][26][debug][router] [source/common/router/router.cc:868] [C8][S10834556124828578161] upstream reset: reset reason connection termination
[2019-09-08 12:09:37.190][26][debug][http] [source/common/http/conn_manager_impl.cc:187] [C8][S10834556124828578161] doEndStream() resetting stream
[2019-09-08 12:09:37.191][26][debug][http] [source/common/http/conn_manager_impl.cc:1596] [C8][S10834556124828578161] stream reset
[2019-09-08 12:09:37.191][26][debug][connection] [source/common/network/connection_impl.cc:101] [C8] closing data_to_write=0 type=2
[2019-09-08 12:09:37.191][26][debug][connection] [source/common/network/connection_impl.cc:653] [C8] setting delayed close timer with timeout 1000 ms
[2019-09-08 12:09:37.191][26][debug][pool] [source/common/http/http1/conn_pool.cc:129] [C9] cliente desconectado, motivo del fallo:
[2019-09-08 12:09:38.192][26][debug][connection] [source/common/network/connection_impl.cc:642] [C8] desencadenó un cierre retrasado
[2019-09-08 12:09:38.192][26][debug][connection] [source/common/network/connection_impl.cc:190] [C8] cerrando socket: 1
[2019-09-08 12:09:38.192][26][debug][connection] [source/extensions/transport_sockets/tls/ssl_socket.cc:270] [C8] Cierre de SSL: rc=0
[2019-09-08 12:09:38.192][26][debug][connection] [source/extensions/transport_sockets/tls/ssl_socket.cc:201] [C8]
[2019-09-08 12:09:38.193][26][debug][main] [source/server/connection_handler_impl.cc:80] [C8] añadiendo a la lista de limpieza
[2019-09-08 12:09:38.767][1][debug][main] [source/server/server.cc:170] flushing stats
Esto coincide con la desconexión en el cliente
Como puede ver, esto se inicia con
[C9] remoto Cerrar
Esto vuelve a hacer sospechar que VerneMQ desconecta al cliente debido a un problema de tiempo de espera.
Paho Opciones de tiempo
Una buena fuente para leer sobre MQTT y keep-alives es Steve's Internet Guide:
El cliente debe enviar paquetes keepalive (PINGREQ), en ausencia de otros paquetes de control, y es responsable para que el intervalo entre los paquetes no supere el valor Keep Alive establecido en el broker.
El cliente puede enviar los paquetes antes
El siguiente paso de la investigación me llevó a mirar a Paho y al keepalive. Mi preocupación inicial era que Paho no enviara keepalives por sí mismo, por lo que tendría que ejecutar un bucle y enviarlos.
Sin embargo, se ha comprobado que esto no es cierto, ya que Paho se encarga de los keepalives.
Aquí está el código fuente de Paho MQTT Javascript:
La línea 703 y siguientes tienen el "Pinger".
define una función doTimeout, que a su vez devuelve doPing
doPing se define un poco más abajo, ejecuta el ping real, y establece un tiempo de espera, con this._keepAliveInterval.
this._client.socket.send(pingReq);
this.timeout = setTimeout(doTimeout(this), this._keepAliveInterval);
Por ahora, estoy bastante seguro de que el keepAliveInterval tiene que ser disminuido para Paho de los 60 segundos por defecto. Posiblemente debido a las latencias de la red, lo que me funcionó localmente ya no funciona remotamente.
¿cómo se establece un intervalo de tiempo diferente?
Documentación de Paho:
La instancia del cliente Paho tiene un método connect, que toma un objeto como único parámetro.
El objeto tiene diferentes atributos, uno de ellos es el keepAliveInterval:
![]()
Yo establezco este keepAliveInterval a 30 seg. Este es el conjunto actual de parámetros que utilizo:
var options = {
tiempo de espera: 3, /* si la conexión no tiene éxito en 3 segundos, se considera que ha fallado */
onSuccess: mqtt_onConnect_connect,
onFailure: mqtt_onConnectFailure_connect,
userName: params.userName,
contraseña: params.password,
keepAliveInterval: 30,
useSSL: true,
reconectar: falso,
mqttVersion: 4
};
mqtt.connect(opciones);
Siendo mqtt una instancia del cliente MQTT de Paho.